「SAP HANAの仕組みがよくわからない」「従来のデータベースと何が違うの?」と疑問に思っていませんか。SAP HANAの仕組みの核心は、データをすべてメモリ上で処理するインメモリデータベースを採用し、圧倒的な高速処理とリアルタイム分析を実現している点にあります。本記事では、SAP HANAの基礎的な仕組みから、主要な機能、導入するメリットまでを初心者にもわかりやすく徹底解説します。
この記事で分かること
- SAP HANAの基本的な仕組みとインメモリ技術
- 従来のハードディスク型データベースとの違い
- 高速処理を支えるアーキテクチャの構造
- 高度なデータ分析や運用管理などの主要機能
- 企業がSAP HANAを導入するビジネス上のメリット
この記事を読むことで、SAP HANAがなぜ次世代システムの基盤として多くの企業に選ばれているのか、その全貌が明確になります。
SAP HANAの基本的な仕組みと特徴
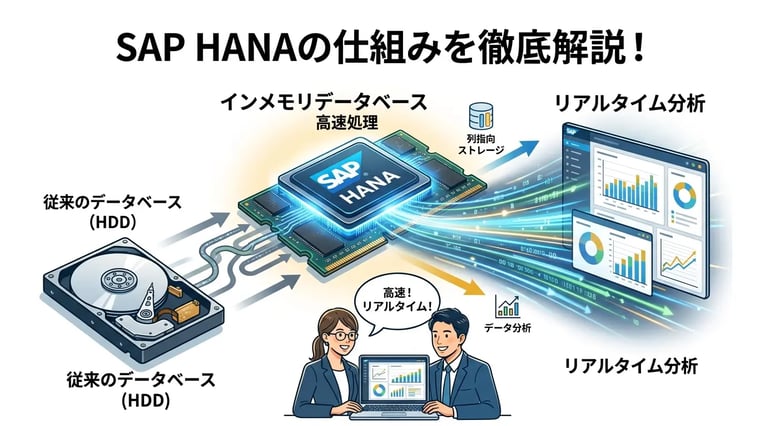
「SAP HANA」というシステムは、俗にインメモリデータベースと呼ばれるものです。従来のシステムとは異なる画期的な仕組みを採用しており、ビジネスに求められるトランザクション処理や分析業務のリアルタイム化を実現するプラットフォームとして位置付けられています。ここでは、その基本的な仕組みと特徴について詳しく解説します。
インメモリデータベースとは
インメモリデータベースとは、原則としてデータをコンピューターのメインメモリ(RAM)上に保持しながら処理を行うデータベースのことです。
ちなみにメインメモリ(RAM)とは、コンピューターが処理中のデータを一時的に保持するための記憶装置で、パソコンの基本スペックとしてもご存知の方が多いでしょう。メインメモリは自由にデータの読み書きが可能な半導体メモリで構成されており、ハードディスクなどのストレージと比べて読み書きが非常に高速です。ただし、メインメモリ上のデータは電源断で失われるため、SAP HANAはメモリ上で処理を行いながら、コミット時のログ書き込みと定期的なセーブポイントによってデータをディスクへ永続化する仕組み(永続化レイヤー)を備えています。これにより、高速性とデータの耐久性を両立しています。
従来のデータベースとの違い
通常、従来のデータベースは、搭載されたハードディスクなどのストレージにデータを保持しながら動作することを基本として設計されています。それに対してSAP HANAは、データの検索や集計などの処理をメモリ上で完結させるため、従来のデータベースに比べて処理が非常に高速になります(データの永続化のためのディスク書き込みは行われます)。
具体的な違いは、下表のとおりです。
| 比較項目 | 従来のデータベース | SAP HANA |
|---|---|---|
| 主なデータ保存場所 | ハードディスクやSSDなどのストレージ | メインメモリ(RAM) |
| 処理速度 | ストレージへのアクセスが発生するため相対的に遅い | メモリ上で処理が完結するため非常に高速 |
| データ格納方式 | 主に行指向(ロー型) | 列指向(カラム型)と行指向のハイブリッド |
高速処理を実現するアーキテクチャ
SAP HANAが圧倒的な処理スピードを発揮できる理由は、単にデータをメモリに置いているからだけではありません。高速処理を実現するために、以下のような独自のアーキテクチャを採用しています。
- 列指向(カラム型)データ格納の採用:データを列単位で保存することで、特定の項目を集計・分析する際の読み込みデータ量を大幅に削減します。
- 高度なデータ圧縮技術:列指向データベースの特性を活かし、重複するデータを効率的に圧縮します。これにより、限られたメモリ空間に大量のデータを保持することが可能です。
- マルチコアプロセッサによる並列処理:最新のマルチコアCPUの性能を最大限に引き出し、複数の処理を同時並行で実行することで、膨大なデータ処理を瞬時に完了させます。
このように、SAP HANAはハードウェアの進化とソフトウェアの最適化を融合させることで、単なる高速なデータベースにとどまらず、ビジネスの高速化というニーズに応えるインメモリープラットフォームへと進化を遂げています。

SAP HANAを構成する主な機能
SAP HANAは、単なるデータベースの枠を超え、ビジネスの高速化とリアルタイムな意思決定を支援する多様な機能を備えています。ここでは、SAP HANAを構成する主要な機能について解説します。
データベースサービス
インメモリデータベースで構成されるSAP HANAは、その最大の特徴でもある高速I/O処理を実現します。ディスクではなくメモリ上でデータを処理するため、従来のデータベースと比較して圧倒的なパフォーマンスを発揮します。
SAP HANAのデータベースサービスにおける主な特徴は、下表のとおりです。
| 機能 | 概要 |
|---|---|
| マルチテナントデータベース | 1つのシステム上で複数の独立したデータベースを稼働させ、リソースの有効活用と管理コストの削減を実現します。 |
| データ階層化(SAP HANA NSE) | アクセス頻度の低いデータをテーブル・パーティション・列の単位でディスク主体の階層(ウォームデータ)に配置するよう指定でき、メモリコストとパフォーマンスを最適化します。 |
| 高可用性とディザスタリカバリ | システム障害時でもビジネスを継続できるよう、堅牢な冗長化構成をサポートします。 |
※SAP HANA NSE(Native Storage Extension):SAP HANAに標準搭載されているデータ階層化機能です。アクセス頻度の低いデータをディスク上に配置し、必要な部分だけをメモリに読み込むことで、メモリコストを抑えながらデータを活用できます。
これらの機能を最大限に引き出すため、使用する環境については、SAP HANA認定により定められたハードウェアベンダーまたはプラットフォーム提供事業者から選択することになります。認定されたインフラストラクチャを利用することで、安定した稼働が保証されます。
高度な分析処理機能
SAP HANAは、トランザクション処理と分析処理を同一プラットフォーム上で実行できるため、データの抽出や変換にかかる時間を排除し、リアルタイムなデータ活用を可能にします。
構造化データと非構造化データの統合
現在求められるデータ分析は、定型化された構造化データにとどまらず、コールログや社内文書、人事情報など、各種テキストベースの非構造化データの活用も求められています。そのため、オンプレミス版のSAP HANAでは、形態素解析やテキストマイニングなどのテキスト分析機能を利用できます(提供される機能はデプロイ形態やバージョンにより異なります)。
さらに、空間データやグラフデータなどの特殊なデータ形式も統合して処理できるため、多様な情報源から多角的なインサイトを得ることができます。
リアルタイムな予測分析
対象データ量の飛躍的な増加に対応するため、機械学習および予測分析アルゴリズム(PAL等)を活用することで、大量データに対する予測分析処理をリアルタイムで実行します。
これにより、過去のデータに基づくレポーティングだけでなく、将来のトレンド予測や異常検知などを瞬時に行い、プロアクティブなビジネス戦略の立案に貢献します。
運用管理と監視
クラウド時代の運用管理基盤であるSAP Cloud ALMをはじめ、アプリケーションの管理や包括的な監視をサポートするSAP Solution Manager(後継はSAP Cloud ALM)、システムランドスケープ全体を一元管理するSAP Landscape Managementなど、豊富なツール群でSAP HANAの管理やデータベースの監視をサポートします。
運用管理において提供される主な機能は以下のとおりです。
- パフォーマンスのボトルネックを特定するリアルタイム監視
- リソース使用状況の可視化とキャパシティプランニング
- バックアップおよびリカバリプロセスの自動化
これらのツールを活用することで、システム管理者の負荷を軽減し、ミッションクリティカルな環境においても安定した運用を維持することができます。
セキュリティとデータ保護
SAP HANAでは、基幹データや経営指標など機密性の高い情報が取り扱われるため、非常に高いセキュリティレベルが求められます。そのため、包括的なセキュリティ機能が標準で組み込まれています。
具体的なセキュリティ対策機能は、下表のとおりです。
| セキュリティ機能 | 詳細 |
|---|---|
| アクセス制御と権限管理 | 職責や特権権限の設定、ID管理により、最小権限の原則に基づいた厳密なアクセス制御を実施します。 |
| データの暗号化 | 通信経路の暗号化に加え、保存データやバックアップデータに対してもFIPS認定の暗号化アルゴリズムをサポートし、データ保護の強化を図ります。 |
| 監査とコンプライアンス | データベースに対するすべてのアクティビティを記録し、不正アクセスの追跡や監査要件への対応を支援します。 |
また、頻発するサイバーセキュリティの脅威に対応するため、SAPのサポートサービスを通じて提供されるSAP EarlyWatch アラートやセキュリティ最適化サービスにより、インシデント発生への迅速な対応や予防保守を支援しています。これにより、企業は安全かつ信頼性の高いデータ基盤を維持することが可能です。
SAP HANAを導入するメリット
SAP HANAを導入することで、企業はデータ活用における多くの課題を解決し、競争力を高めることができます。ここでは、主なメリットについて解説します。
ビジネスの高速化とリアルタイム経営の実現
SAP HANAの最大のメリットは、インメモリデータベースによる圧倒的な処理速度の向上です。これにより、膨大なデータに対する分析や集計を瞬時に実行し、リアルタイム経営の実現に大きく貢献します。
現代のビジネス環境では、社内業務プロセスの変化や消費者の購買行動の多様化など、市場のニーズに柔軟かつ迅速に対応することが求められています。SAP HANAを活用することで、経営層から現場の担当者まで、常に最新のデータに基づいた意思決定が可能になります。
従来のデータベースとSAP HANAによるビジネスへの影響の違いは、下表のとおりです。
| 比較項目 | 従来のデータベース | SAP HANA |
|---|---|---|
| データ処理速度 | ディスクへのアクセス制限により、大規模データの集計に時間がかかる | インメモリ処理により、瞬時にデータの集計や分析が完了する |
| 意思決定のタイミング | バッチ処理後の過去データに基づくため、タイムラグが発生する | リアルタイムなデータに基づくため、即座な意思決定が可能 |
| ビジネスへの対応力 | 市場の変化に対する反応が遅れがちになる | 変化に対して柔軟かつ迅速に対応できる |
業務データの一元管理
SAP HANAは、単一のインメモリプラットフォームとして、ERPシステムを中心とした基幹データから、関連する外部システムのデータまでを一元的に管理できる点も大きなメリットです。
通常、トランザクション処理と分析処理は異なるデータベースに分けて運用されることが多く、データの同期や重複管理の手間が発生していました。しかし、SAP HANAはこれらの処理を同一プラットフォーム上で統合して実行できます。
データの一元管理によって得られる具体的なメリットは、以下のとおりです。
- データの重複や不整合を排除し、常に正確な情報を維持できる
- データ転送や抽出のためのバッチ処理が不要になり、運用コストを削減できる
- 構造化データだけでなく、テキストなどの非構造化データも統合して分析できる
このように、SAP HANAは単なる高速なデータベースにとどまらず、ビジネス全体に求められるデータ活用を支える強力な基盤となります。すでにSAP製品を利用している企業にとっては、SAP HANAプラットフォームをベースにした次世代システムへの移行が、デジタルトランスフォーメーションを推進する最有力な選択肢となります。
SAP HANAの仕組みに関するよくある質問
SAP HANAは従来のデータベースと何が違いますか?
データをメモリ上で処理するインメモリ技術により、圧倒的な高速処理が可能です。
SAP HANAは非構造化データを処理できますか?
テキストなどの非構造化データと構造化データを統合して処理できます。
SAP HANAで予測分析はできますか?
分析エンジンを内蔵しており、リアルタイムな予測分析が可能です。
SAP HANAのセキュリティは安全ですか?
暗号化やアクセス制御など、高度なデータ保護機能を備えています。
SAP HANA導入のメリットは何ですか?
データの一元管理と高速処理により、リアルタイム経営を実現できることです。
まとめ
SAP HANAは、インメモリ技術による超高速処理を仕組みの基盤としています。従来とは異なり、データの一元管理やリアルタイムな予測分析を可能にし、企業のリアルタイム経営を実現する強力なデータベースです。
当社はSAPのスペシャリストとして、豊富な知見と実績をもとに、最適なソリューションをご提案します。SAPに関するご相談やお見積りのご依頼は、ぜひお気軽にリアルテックジャパンにお問い合わせください。