今回Nutanix社から機材を提供頂き、実機検証をする機会をいただきました。
検証結果はついては、【技術白書公開】SAP on Nutanix 基本性能検証結果報告書からダウンロード可能ですが、そこに書きれなかった内容を補足説明させて頂きます。
ハードウェアの入れ替えを含むプロジェクトで毎回苦労するのがハードウェアの監視です。SNMP trapやメールによるアラート通知を利用したりしますが、通知メッセージの内容がわかりにくく場合が多いように思います。
監視にもNutanixの強みがあります。NutanixはHypervisorとサーバーの中間に位置し、かつクラスター化されているという特性から、ハードウェアの監視もクラスター単位で一元化されています。Nutanixで用意されているアラートには、サーバーダウンはもちろんMemory、ネットワークインターフェースカード、ディスクの異常、さらにはサーバー内のFanの劣化、電源ユニット障害や温度異常まで幅広い項目がカバーされています。また、CPU、Memoryやディスクの空き容量の監視もできます。こうした各種アラートがPrism (GUIのWeb管理画面)に集約されており、これまでのハードウェアでは個別に構築の必要があった監視ソフトが標準で内蔵されているという感じです。


Prismでの目視だけでなく通知が必要であれば、Email通知やSNMP trapを利用できます。これまでのハードウェアのSNMP TrapだとTrapの内容を理解しサーバーの特定等の作業が必要でしたが、NutanixからのTrapに対する最初のアクションはPrismのアラート画面の確認となるので、運用オペレーションをシンプルにできます。
また、Email通知をNutanix社のサポートへ直接送信することも可能ですので、送信設定をしておくとハードウェア障害が疑われるアラートが送信された場合、NUTANIX社から確認の連絡を受けることができますのでさらに安心です。
Hypervisor以下の監視はNutanixの標準機能でカバーして、OSの死活監視やアプリケーションレベルの監視をSAP Solution Manager等の監視ソリューションでカバーすることでハードウェアからアプリケーションまでもれなく監視できるようになります。
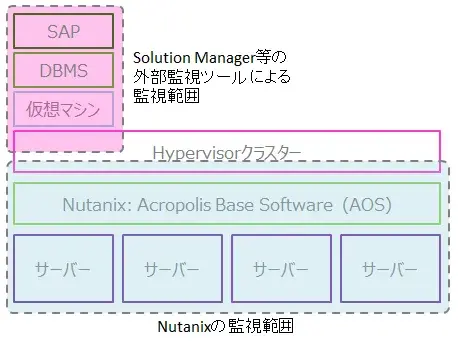
インフラ運用をアウトソースしている等の理由から、Prismの利用が難しく、すべてのアラートを所定の形式で監視ソリューションのコンソールに表示する必要がある場合は、NUTANIXの持つREST APIを利用するスクリプトをPowerShellやPythonで作成することができます。NUTANIXのマニュアルにスクリプトのサンプルを含む丁寧な説明がありますのでそれほど工数をかけずに作成できそうです。
とはいってもPrismはよくできていますので、監視コンソールに統合するより、Prismをそのまま活用する方が導入工数と運用工数の両面でメリットがあるかもしれません。