2016/4/28発行の日経コンピュータ本紙で「ハイパーコンバージドの実力、サーバ50台を2Uに集約」で特集が組まれており、ご覧になられた方もいらっしゃるかと思います。
ハイパーコンバージドインフラ(Hyper Converged Infrastructure、略称HCI)という呼び名ですが、Convergeの語源はラテン語のconvergere 「いっしょに傾く」というのが語源とのことで、日本語だと「収束する」とか「集中する」とかの意味です。数年前にハイパーが付かない「コンバージドインフラ」というのが先に出て、1つのラックにサーバ、共有ストレージ、ネットワーク、管理ソフトウェアを一つにまとめられたものを「垂直統合型システム」と当時は訳されたりした結果かどうかはわかりませんが、基盤構築時に必要な製品の単なる寄せ集めの延長線で、間違って捕らえられることが少なくありません。
今回は序章ということで、「HCIで何ができるの?、SAP環境としてどうなの?」という個別の技術の話はあえて横に置いておいて、今までのIT基盤と何が違うのかという点から、今のHCIの実像を読み解いていきたいと思います。
HCIでは外付けの共有ストレージがない
従来型のシステムを比べた場合の一番のわかりやすい違いはこれで、全てサーバ本体内蔵のストレージで賄われています。
下記に簡単な絵を描いてみましたが、HCIはサーバ内蔵ストレージを複数サーバに跨がって束ねることにより、大きなストレージプールを作成し、そこにデータを分散して格納するということです。ハイパーバイザとしてはVMware、Hyper-Vなどがサポートされており、ディスクのスナップショット(複製)機能なんかもあります。
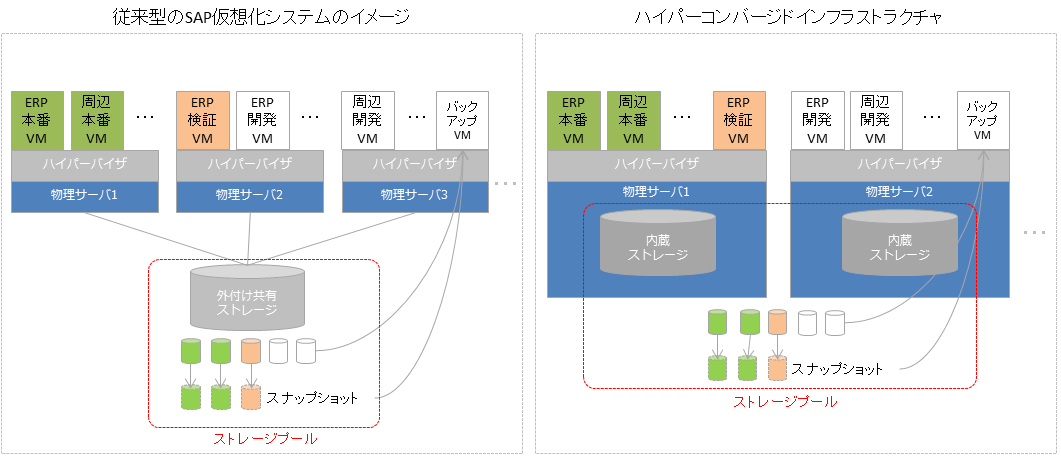


HCIではソフトウエアを使ってサーバ内蔵ストレージを束ねる仕組みがある
各物理サーバ上には「ストレージコントローラ」機能を担うVM環境が下記の例では存在しており、そこを通じて各サーバにある内蔵ストレージが連携しています。
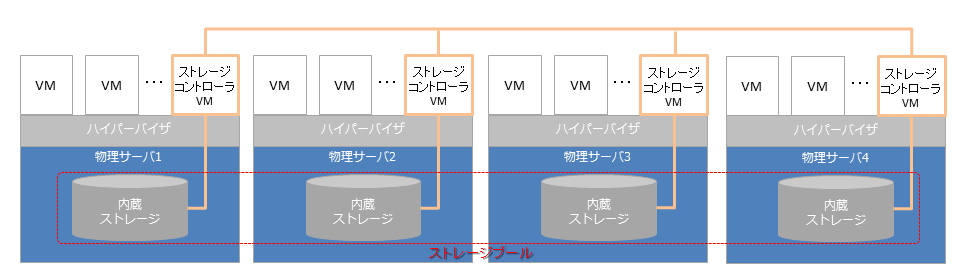
VM環境とすることで特定のハイパーバイザーに依存しないのが利点ですが、ハイパーバイザの中に実装されている製品もあります。
次は書込(Write)時の動作イメージですが、一番左にあるVMからローカルの内蔵ディスクに書き込み(W)がなされると、別のサーバ内のストレージに同時に書き込まれます。
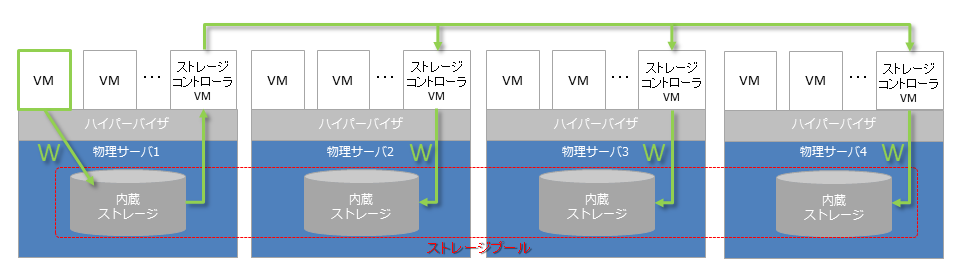
従来専用のハードウェアで提供されていたストレージ機能の多くがソフトウェアで実装されているため、このあたりをSDS(Software Defined Storage)と呼ばれる所以です。
分散ストレージでシステムの運用がどう変わるのか
分散ストレージを実現することで今までのサーバ運用が大きく変わることを、クラウド黎明期を振り返りながら説明します。
2008年当時のzdnetさんの記事「グーグルデータセンターの内側--明らかにされた独自性」にあるように、当時も今も最先端といわれるGoogle社のデータセンター内部がYoutubeで公開されました。
たかだか5分の動画ですが、エッセンス満載で事情通を唸らせたのは言うまでもありません。
今回はGigazineライクに動画をプレビューしてみたいと思います。
2Uの自社製サーバがずらっと並んでいます。
当時は分散ストレージ自体がそれほど知られていなかった時代で、「あれっ、ストレージはどこにあるの?」と探した思い出が・・・

ディスク障害が発生したサーバを、ラックから引っこ抜いています。

サーバから故障ディスクを取り出して、

バーコードで故障ディスクのインベントリをスキャンして、

セキュリティ確保の観点からディスクを物理破壊しています。

あっという間にスクラップにしてしましました。

ここからが勘所です。
キックスケーターに乗って、DC内を軽やかに移動する画面です。
このシーンは当時有名になりましたね。それだけデータセンターが広いんだと。
この一見余裕とも思える状況について正しい理解が重要ですが、目の前で起こっている事実を今一度まとめてみましょう。
・ディスク障害が起こっていることをあえて露呈している。
・サーバ毎引っこ抜いてしまったので、そこで稼働していたアプリは完全停止している。
上記の状況が発生しているとは、とても思えない和やかな雰囲気の中で、メンテナンス作業が続けられているように見える。
つまり、この動画を見ているユーザーからクレームが来てもおかしくない状況をあえてアピールしています。
あと、バックアップデータを戻したり、サーバを立ち上げ直すといったシーンがそもそもないというのも印象的です。

翌年Google社から「The Datacenter as a Computer(*注)」が発行され、そこに答えがありました。
*注: Publickeyさん にて書籍「The Datacenter as a Computer」の第二版がPDFで無料公開中!現在は改訂版が書籍で出版されており古いですが、今読んでも参考になり、お勧めします。
上記ドキュメントの中にクラウドのデータセンターではハードウエアの保守作業は「バッチ処理のように行う」とあり、すなわち故障したからといってすぐには修理はされません。
どこかのサーバのディスクが飛んでそこで稼働していたVMはいったんはダウンしたとしても、他のサーバに格納されたデータをもとに別のサーバ上から必要なデータをロードすることによって、その後速やかに自動復旧することを意味しており、そこには人が介在しません。
以上はサーバのディスクが故障した例をもとにしていますが、動画のコメントには冷却システムを5回以上変更しているとあるように、設備変更等での計画停止時に影響がない別ラック上のサーバに一時的にまとめて移設するといったことも容易に実現できているようです。
ここまでGoogle社のData Center の動画をベースに、これからのIT基盤像の一例をで説明してきました。
閑話休題
これから先はGoogleクラウドで採用されている分散ストレージと同様の機能をHCIがどう実現しているかという話です。
ある物理サーバで稼働していたVMがダウンしたとしても、別サーバに分散格納されていたデータを読みこむことで、別のサーバ上でVMを立ち上げることが可能になります。その際には専用の待機サーバは不要で、全てのサーバで相互にフェイルオーバーが可能なので、そのための専有リソースは最小限です。下記の例では、一番左の物理サーバで稼働していたVMが一番右のサーバ上でVMとして立ち上がるイメージの例です。
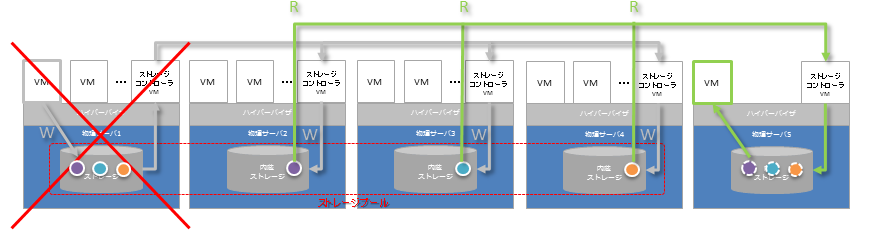
この仕組みがあることで、数千台のサーバをたった1人で面倒見るということに関して真実味が少しでも実感頂ければ幸いです。
また、上記のことができるということはリソースの拡張も簡単です。
フォークリフトアップグレードと海の向こうでは呼ぶらしいですが、リソースが足りなくなったら下記のように簡単にボックス単位で拡張することにより、自社のクラウド環境に俊敏性をもたらします。
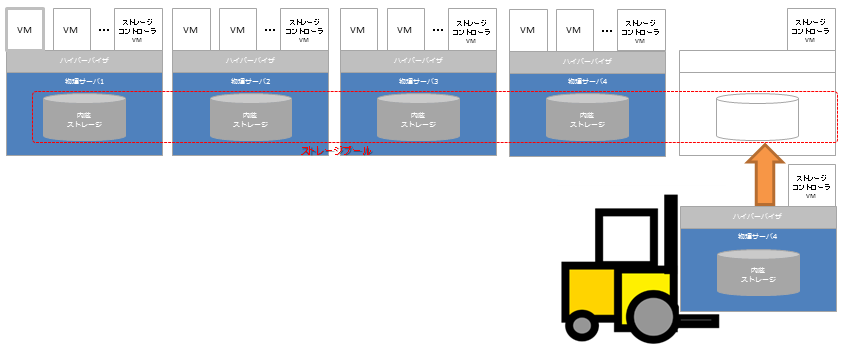
しばしばHCIは「Cloud Nativeのソリューション」といわれますが、これがその背景となる一つの側面ですHCIは「Cloud Nativeのソリューション」といわれますが、これがその背景となる一つの側面です。
少しはイメージつきましたでしょうか。
今回の記事を「サーバ仮想化の次の一手」とタイトルに銘打ちましたが、HCIは要チェックです。
次回以降、さらに掘り下げていきたいと思います。
長文最後までお読み頂きありがとうございました。