HANA Voraの位置づけ
実は、HANA VoraはSAPのプラットフォーム戦略上も核となる位置づけになっています(SAPPHIRE 2016資料 P21参照)。図上ではHANAと同格なほどです。
HANA Vora概要について前回記事「短時間で理解するHANA Vora入門 概要編」で解説しました。今回はその後編として、HANA Vora基本動作と特長について説明します。


HANA Vora基本動作(テーブル定義、メモリロードからクエリ実行)
まずはHANA VoraのシェルをSSHクライアントから起動します。
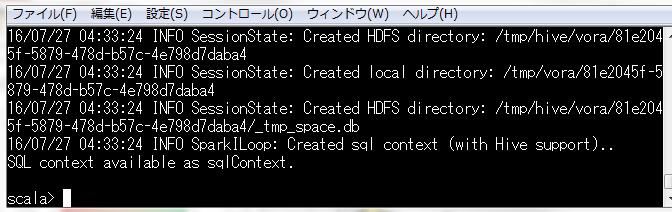
YARNモードでシェルを起動したため、YARNでSpark Executorが見えます。この動きおよび見え方はSparkと変わりがありません。
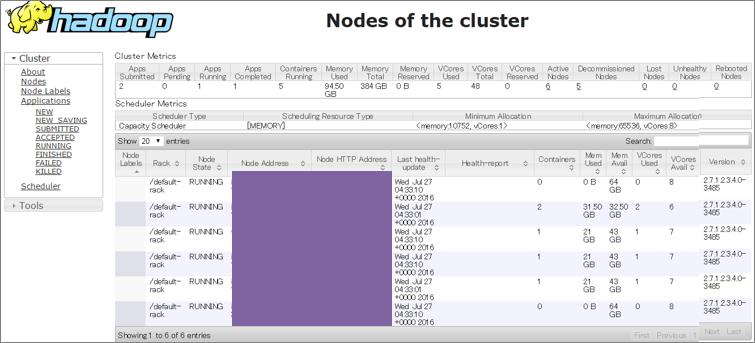
では、HANA Voraでテーブル定義をし、HDFSに置いている1GBのファイルをロードします。データが3つのノードに分散されてメモリロードされているのがわかります。
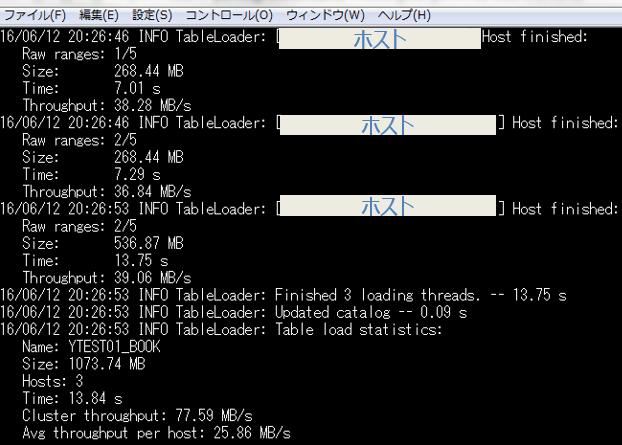
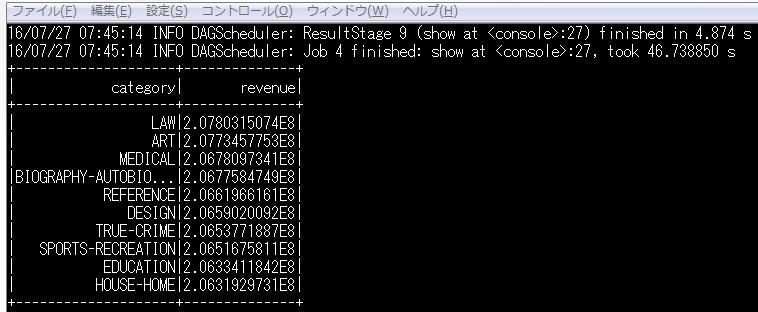
クエリを実行してみます。クエリ結果がシェル画面で見えます(実際にはエンドユーザは使わない画面ですが、技術者が簡易的に結果確認ができます)。
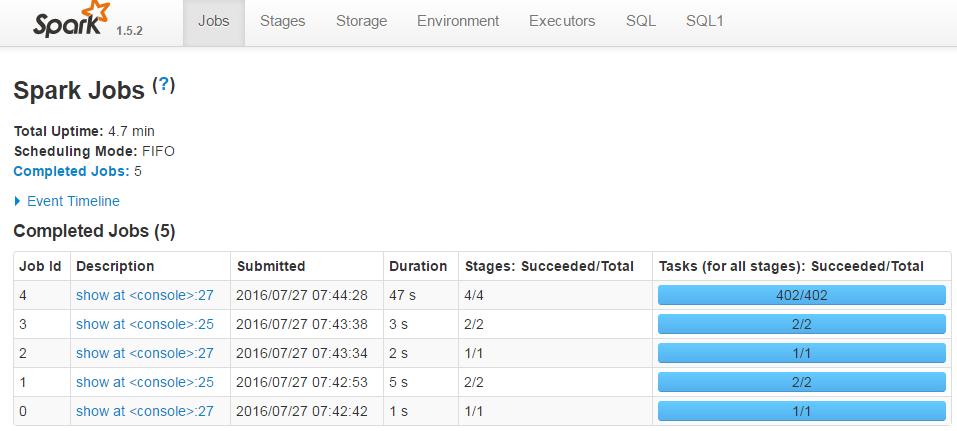
実行処理をSparkのUIで見ることができます。上画面ショットはJob単位のログで、下画面ショットはStage単位のログです。Stageのレベルで見ると処理が分散されているのがわかります。
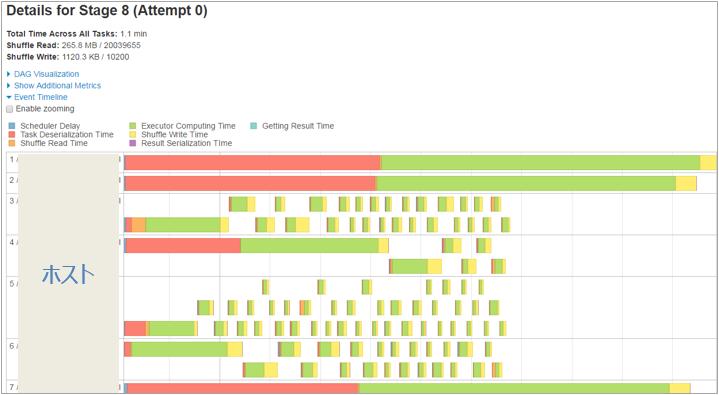
これまでの動きを画面を通して見るとわかりますが、HANA VoraはSpark、YARNと協調して動きます。
HANA Voraの特長
1. OLAP機能強化
前者は、組織や品目などを階層構造を使ってレポーティングするための機能です。リンク先動画にわかりやすく紹介されています。
後者は、レポートでインタラクティブにドリルダウンをするために使用できます。ShellやHANA Vora ToolからSQL(DDL)で定義できます。また、リンク先記事でも紹介されているようにモデラーツールでも定義できます。
2. HANA連携
HANAからSpark/Hadoopへの連携では、Smart Data Access(以下、SDA)という機能がありました。簡単に言うとSmart Data Accessよりも速く安定した連携が可能となります。SDAはODBC/JDBCドライバに依存していたり、Hadoopディストリビューション間で互換性がないといった問題がありました。それに対して、HANA VoraではSAP製のSpark Controllerというコンポーネントを通すことでスピードと安定性を担保しています。
3. Spark高速化
では、どれだけ処理高速化が実現できるのでしょうか?Sparkと処理時間の比較してみました。
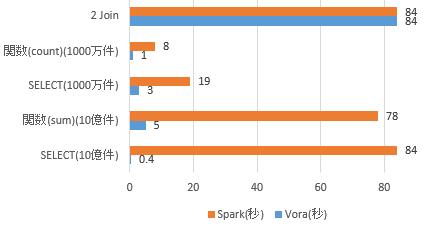
単一テーブルに対する処理は非常に速いです。Joinの場合はあまり変わらなくなってしまっています。用途に応じてHANA Voraを活用する領域を考慮する必要が多そうです。
「3. Spark高速化」の検証詳細
検証環境
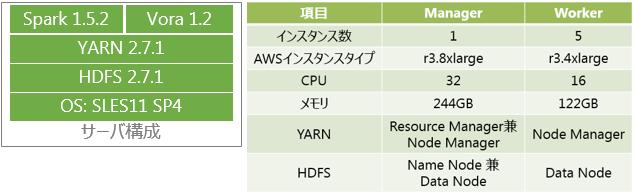
- HDP2.3.4
クラスタマネージャ
- YARN(Spark/HANA VoraをYarnで実行)
- HDFSと同居
データストレージ
- HDFSにCSV形式
- YARNと同居
Spark(HANA Vora)実行時パラメータ
- クラスタ全体のExecutor数:12
- ExecutorあたりのCore数:4
- Executorあたりのメモリ割当:12GB
テストデータ
テストデータはAWSのツールを使いました(Impala用とありますが、Spark/ HANA Voraでも使用可能です)。
Transactionを47GB(約10億レコード)、booksを1GB(約1000万レコード)で作りました。
実行クエリ

HANA Voraの今後
この記事に関するサービスのご紹介

導入/移行(プロフェッショナル)サービス
プロフェッショナルサービスでは主にSAPシステムの導入や移行、それに伴うテクニカルな支援を行います。ERPやS/4 HANA、SolManといった様々なSAP製品の新規導入、クラウドを含む様々なプラットフォームへのSAPシステムの最適な移行、保守切れに伴うバージョンアップ・パッチ適用等の作業だけでなく、パラメータ設計、パフォーマンスチューニング、導入・移行計画支援等についても対応いたします。
詳細はこちら