コンビニのセミオート発注
弊社の近くにはローソンがあって、よく利用しています。コンビニには弁当・飲料・お菓子など数えきれないほどの商品が陳列されていて、ついつい買い物をしてしまいます。ローソンは、それらの商品を欠品しないようにセミオート発注という手法を使っています。会員データのビッグデータを活用して品揃え、発注数量等を提案する発注方法です。その裏側の仕組はHadoopを活用しています。


HANA Voraに関しては、以前の記事「HANA Voraの基本機能を読み解く~インメモリクエリエンジン他~」も参照ください。SCN記事「SAP HANA Vora 日本語情報まとめ」もわかりやすいです。
ビッグデータの価値
そもそもビッグデータにどんな価値があるのでしょうか?ビッグデータの管理はコストもかかりますし、難しい点も多いです。
ひとつの大きなメリットは、新しい価値・発見が見つかる可能性が大きいという点です。ビッグデータを蓄積するだけでなく、統計的な手法を使ってデータ間の関連性や新しい法則などを見つけることが技術的に可能になっています。統計的な手法を使う場合に、データ量が小さいよりも大きい方が発見できることが多いですし、何かを実施するときの効果も大きくなります。このあたりは、過去記事「予測分析(Predictive Analysis)でシステムの価値を高める(前編)」でも解説しています。
Hadoop、Spark、HAVA Voraの歴史
Hadoopはビッグデータ処理を支えるオープンソースのフレームワークです。2006年にVer0.1がリリースされ、Yahooを筆頭にして多くの企業で利用されています。
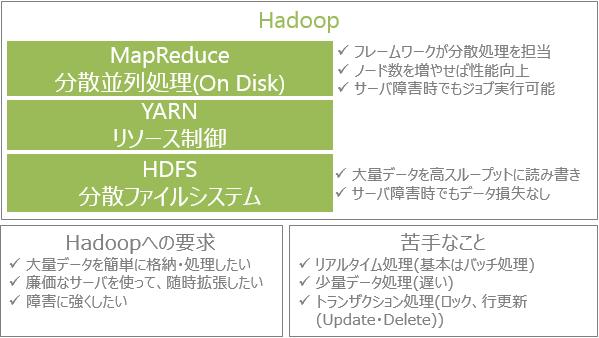
Hadoopを速くするためのフレームワークとして、Sparkが登場します。Hadoopでは、ディスクに読み書きしていた処理の途中経過をメモリを使うことによって処理高速化の実現をしています。
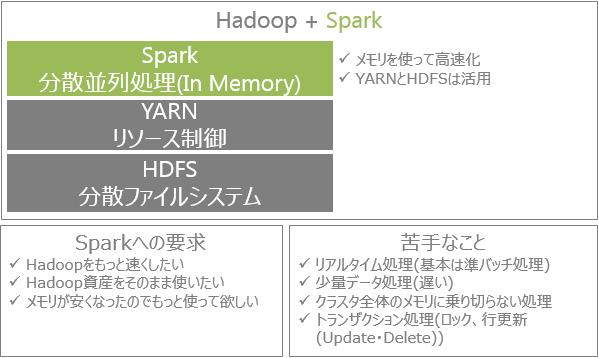
2015年にSparkと連携するHANA VoraをSAP社がリリースします。
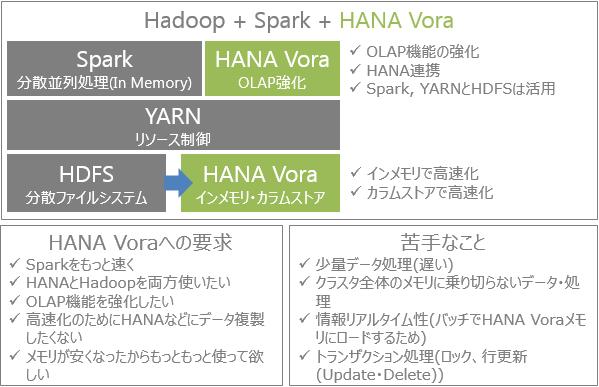
それぞれとHANAを比較してみました(比較評価は、わかりやすさに重点をおいており正確ではありませんのでご注意ください)。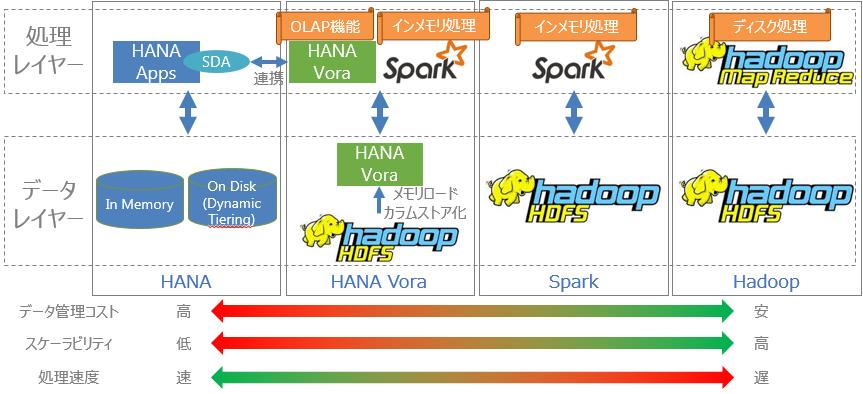
Ver1.0で時系列に比較してみると似たようなタイミングとなっているのが興味深いです(HadoopやSparkはVer1.0リリースまでの時間がある程度あります)。まるで、ビッグデータ基盤とRDBMSが両方から手を伸ばして、隙間を埋めているように見えます。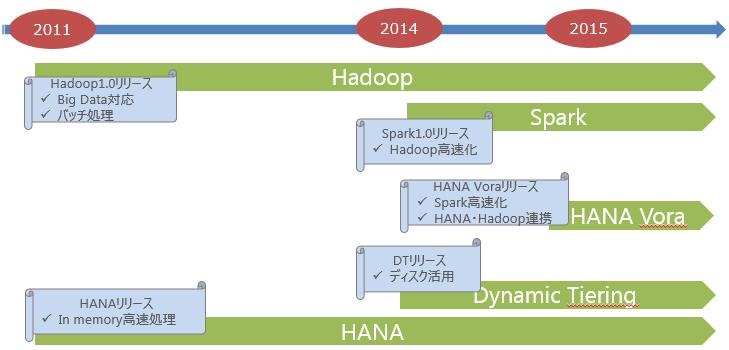
三者択一ではなく組み合わせ
次回は「詳細編」です。ご期待ください。