2015年9月にSAP社から製品発表されたHANA Vora(ハナ ボラ)、2016年4月にHANA Vora 最新版V1.2がGAになったことで、いよいよこれからという感じです。製品の役割がビッグデータ基盤としての今後のスタンダードでもあるSpark(スパーク)との連携強化ということで旬なこともあり、技術検証が世界中で始まっています。
かくいう弊社もそのうちの一社ですが、現場はかなり汗かきました。要はSAP側の人はSparkがわからない、Spark側の人はSAPがわからないということで、かなりの確率で技術的な勘違いとか誤解が生まれ、そこにオープンソースならではの技術的な緩さとSAP製品サポートの狭間の現実が絡んで来ることで、現場的には「どこがどうなっているのかさっぱりわからん」状態になりえます。
実際にエンドツーエンドで動かしてみた感覚をもとに、若干見切りが甘いところはありつつSAP側の技術者の観点からHANA Voraの基礎を読み解いてみたいと思います。今回のお題はSAP社の公式サイトにあるHANA Vora の製品概要で、主要な技術機能であるインメモリクエリエンジンがメインになります。
インメモリクエリエンジン
SAP社の説明文には「インメモリクエリエンジンをApache Spark実行フレームワーク上で実行することができます。クエリーをコンパイルして複数ノードにまたがる処理をスピードアップし、OLAP分析を高速化かつシンプル化します。」とあります。
実態は書いてあるとおりなのですが、実際に稼働させてみないと正確な理解は難しい内容と思います。特に日頃ERPをやっているエンタープライズ系の人間からするとApache Sparkがそもそもしっくり来ません。ググってみたらBigDataとかHadoopとかキーワード見つけて、なんかよくわからないけどSpark上にあるビッグデータをHANAのインメモリ技術を使って爆速でクエリするんだろうと思ってしまう方がほとんどではないかと思いますが、実態がわかると、「えぇ、そういうことなの!」ってなること必至です。
早速はじめましょう。
「HANA VoraはHANAサーバで動くのですか?」
いいえ、HANA Voraというソフトウェア自体はインメモリデータベースと呼ばれるHANAサーバには通常インストールしません。
ここはHANAという一言が先頭についている故に勘違いし易い点で、分かり易い例としてはHANAのサーバやDBMSがなくてもHANA Voraは稼働させることができます。ではどこで稼働するかというと、最初の説明文の通り「Apache Spark実行フレームワーク」と共存する形で稼働させることになります。
「インメモリはどこにあるの?」
ここが勘所なのですが、弊社もまだ完全に見切れているわけではありません。
しかし、インメモリは実体として下記の2つの観点で関与しているだろうと弊社は考えています。(間違っていたらすいません。)
HANA Vora自体が、HANAの製品コンセプトがベースとなってC++で開発された。
SAP TechEd、Las Vegasのプレゼンテーション「SAP HANA Vora -- Why We Developed It and Where We Plan to Go with It」の冒頭1:30からの説明にキーワードがありました。
具体的には下記6つのTechnical Point of View を示した上で、HANAを置き換える製品ではなくHANAを拡張する製品であることが明言されています。
- In Memory Storage
- Compressed Columns
- Parallel Query Processing
- Fast Column Scan
- Cache-Efficient Algorithms
- Code Generation
これが理由で製品名の先頭にHANAという言葉がついているんだと考えれば、しっくりきます。
ちなみにVoraは「食欲旺盛な」という意味の「voracious」に由来しており、データに対する旺盛な意欲を表している造語とのこと。
一方でSpark自身もインメモリのコンセプトが盛り込まれている。
Sparkは大規模データを分散処理を実現するプラットフォームのことで、複数のIAサーバを束ねて1つのシステムとすることで、高速かつ汎用的に作られており、大量データの格納や分析に適しているために最近のビッグデータ向けの主要ソリューションです。
今やSparkは、Apacheプロジェクトのトッププロジェクトの一つであり、Hadoop(ハドゥープ)のオリジナル開発者からもSparkに対する前向きなコメントがあるように、素性のよいオープンソース環境と考えられます。
Hadoop(ハドゥープ)という名前自体は、本ブログの読者であれば一度は聞いたことがあると思います。このHadoopとよく比較される分散処理基盤がSparkなのですが、Hadoop基盤は下記のような複数のソフトウェアが搭載されています。
- Hadoop MapReduce:分散処理フレームワーク
- HBace:分散データベース
- HDFS(Hadoop Distributed File System):分散ファイルシステム
この中でMapReduce (マップリデュース)と置き換わることを目指しているのがSparkであり、高速な分散処理を謳っているのですが、それを実現するあたってインメモリのコンセプトが実際に使われています。その技術背景としては下記の通りです。
MapReduceによる分散処理はバッチ処理の考え方が根本にあります。複数のノードに対してジョブを分散実行させる際に、対象となるデータをHDFSから取得→処理→HDFSに出力→HDFSからデータ取得→処理といった形で処理することが考えられます。特に処理を繰り返すアルゴリズム(機械学習、グラフ描画)や対話型のドリルダウン分析(EXCEL,R)の利用を想定した場合、複数のノードを立ち上げて、都度HDFS(ディスク)から読み込んで処理することになるため、ディスクアクセスによるオーバヘッドが高く、処理に時間を要することが容易に想像できます。Sparkでは中間結果をHDFS(ディスク)に書着込まないコンセプトすなわち繰り返し利用するデータについてメモリ上に保持する仕組みを持ち込むことで、MapReduceの100倍早いという触れ込みがあります。その際の技術キーワードとしてはRDD(Resilient Distributed Dataset)という抽象化データセットとDAG(Directed Acyclic Graph)という実行エンジンの実装が寄与しているそうです。
この事実がHANA Voraとどう関連しているかは執筆時点で全く見えないのですが、処理全体の高速化という観点で寄与していることは間違いないと考えています。
説明が長くなりましたので、今まで説明してきた製品の実体を纏めたいと思います。
下記の表はSAP社のプレゼンにあった内容をもとに弊社で独自に追加補足したもので、SAP HANA Platformは、従来からHANAサーバとかHANAデータベースが稼働するプラットフォームを指しています。
| Spark | SAP HANA Vora | SAP HANA platform | |
| 説明 |
Hadoop向けのインメモリーデータ処理を実現のためのフレームワークで、最もポピュラーなオープンソースソフトウェアのこと |
インメモリクエリエンジンであり、Spark実行フレームワークにプラグインする |
インメモリでのデータ及びアプリケーション基盤のこと、データセンターやクラウド向けにミッションクリティカルな実装要求をサポートするためのACID準拠 |
| 要点 | Hadoop向け | Hadoopを使ったエンタープライズ向けアプリケーション、分析 | エンタープライズ向けアプリケーション、分析 |
| ・データパイプラインを構築するための単一フレームワーク | ・Hadoop上のデータに対して、データ階層や時系列階層を用いることで、より高機能な会話型クエリによる分析実施 ・コンパイルされたクエリによる複数ノードを跨がるクエリ処理の高速化 |
下記の用途で中核となる開発実装プラットフォーム ・トランザクションと分析の両方を満たすハイブリッド型新世代アプリケーション ・アプリケーションに埋め込まれたリアルタイム分析、又はエンタープライズ向けアナリティクスシステム群(データマート、データウェアハウス、データレイク)を跨がるリアルタイム分析 |


データの階層構造
強化されたマッシュアップAPI
「Spark SQL Data Source APIに基づく高度なマッシュアップを使用することで、ユーザー自身が企業のソースからプロジェクションを作成してデータセットを強化することができます。
強化されたSparkおよびSAP HANAアダプター
SAP HANAとApache Sparkの間のデータ移動を超高速化して、パフォーマンスを改善します。
オープンな開発インターフェース
今回は省略します。
まとめ
VoraはSpark SQLの機能拡張が行なわれているだけでなく、Yarn上で稼働するSparkの機能拡張も合わせて行なわれていることがわかります。
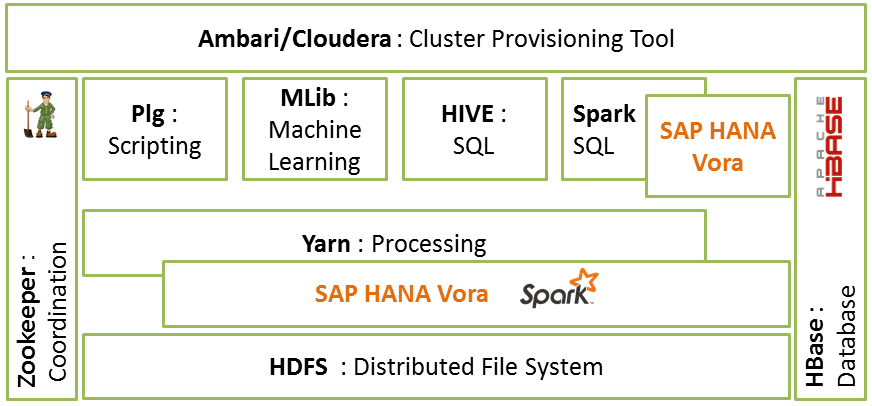
まだまだ説明が足りないがところありますが、今回はこれで終わりとさせて下さい。
長文最後までお読み頂きありがとうございました。
弊社で実施した技術検証結果について後日公開させて頂く予定です、お楽しみに。

この記事に関するサービスのご紹介

導入/移行(プロフェッショナル)サービス
プロフェッショナルサービスでは主にSAPシステムの導入や移行、それに伴うテクニカルな支援を行います。ERPやS/4 HANA、SolManといった様々なSAP製品の新規導入、クラウドを含む様々なプラットフォームへのSAPシステムの最適な移行、保守切れに伴うバージョンアップ・パッチ適用等の作業だけでなく、パラメータ設計、パフォーマンスチューニング、導入・移行計画支援等についても対応いたします。
詳細はこちら