はじめに
S/4HANAの勘所シリーズとして、HANAの最新技術を使った顧客分析のデモシナリオを作ってみました。本記事の内容は、ノーコーディングで実装しています。プログラムにアレルギーを持っている人でも実装可能なシナリオです。
そもそも分析という行為は、事象に応じて試行錯誤をしながらさまざまな角度から実施することも多いです。そのたびに開発のような手間がかかることをしながら分析するのではなく、少ない手間で実施するのが理想的です。
システムはHANAではありませんが、「【SAP BWで最新SQLServer活用】第3部 誰もが柔軟に活用できるBIフロントエンド(MS Excel)」と概念的に共通する内容も多いので参考にしてください。
なお本記事は、下記シリーズ記事の一部で、他記事も参照されることをお勧めします。
第1回 S/4HANAの勘所:HANAの歴史と概要
第2回 S/4HANAの勘所:HANA Viewを使った分析高速化


第3回 S/4HANAの勘所:HANA AFMとAFLを使った統計解析
第4回 S/4HANAの勘所:HANA XSエンジンを使ったWebアプリケーション
第5回 S/4HANAの勘所:HANA基本実践編(PALとLumiraを使った顧客分析) 【本記事】
第6回 S/4HANAの勘所:HANA応用実践編(PALとUI5を使った顧客分析)
こちらの「SAP S/4HANAで何が実現できるのか?」についてもっとご覧ください。
業務シナリオ
今回のデモでは業務シナリオとして、以下の状況を想定しています。
【業種】アパレル小売
【業態】通販
【目的】上顧客の離反防止
【詳細状況】過去の上顧客からの注文が最近減っているように感じている。強い競合他社の出現や自社ブランド衣服のデザイザー変更等、さまざまな原因が考えられる。離反客を対象としたイベントを実施して、その原因追求をしていきたいと考えている。そのためにまずは離反客を抽出したい。
【実施手順】
下図のアーキテクチャに則って、下表の手順で分析していきます。
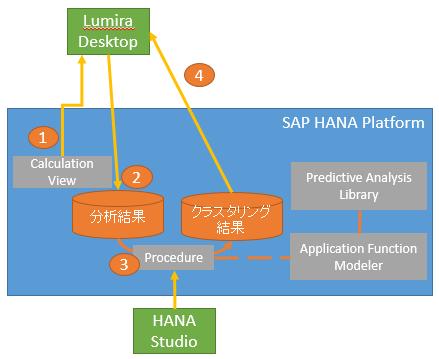
| No. | 内容 | 使用ツール |
|---|---|---|
| 1 | 過去3年間における売上TOP300の顧客を分析 | Lumira Desktop |
| 2 | Lumiraで抽出した顧客データをHANAに保存 | Lumira Desktop |
| 3 | 顧客をいくつかのかたまり(クラスタ)に分類 | HANA Studio |
| 4 | 顧客分類結果を確認 | Lumira Desktop |
※何点か用語の解説です。
- Lumira Desktop:データ分析をデスクトップで行うためのBIツール。
- PAL(Predictive Analysis Library):クラスタリング等の予測・分析をするための関数群。
- Calculation View:HANA Viewのひとつ。テーブルやViewを結合して定義する柔軟なビュー(計算処理や複雑な結合に対応可能)
- HANA Studio:Eclipseをベースにした統合開発環境。HANAに対して開発・設定・管理をするために使用する。
- Application Function Modeler:通称AFM。ノーコーディングでプロシージャを定義できるモデリングツール。
デモ詳細
【手順1】過去3年間におけるTOP300の顧客を分析
Lumira Desktopの下図の画面で過去3年間売上TOP300の顧客情報を分析します。まずは、LumiraからHANAのCalculation Viewを選択し、下図の画面で抽出対象となる対象期間や上位数を最初に入力しています。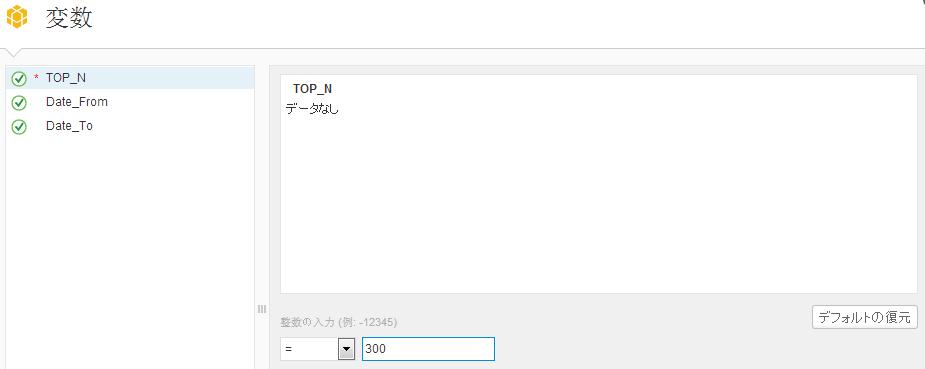 下図は分析画面です。きれいなグラフで分析軸や対象が表示されます。RFM分析ができるようRecency(最新購買日), Frequency(頻度), Monetary(購入総額)を分析対象にしています。
下図は分析画面です。きれいなグラフで分析軸や対象が表示されます。RFM分析ができるようRecency(最新購買日), Frequency(頻度), Monetary(購入総額)を分析対象にしています。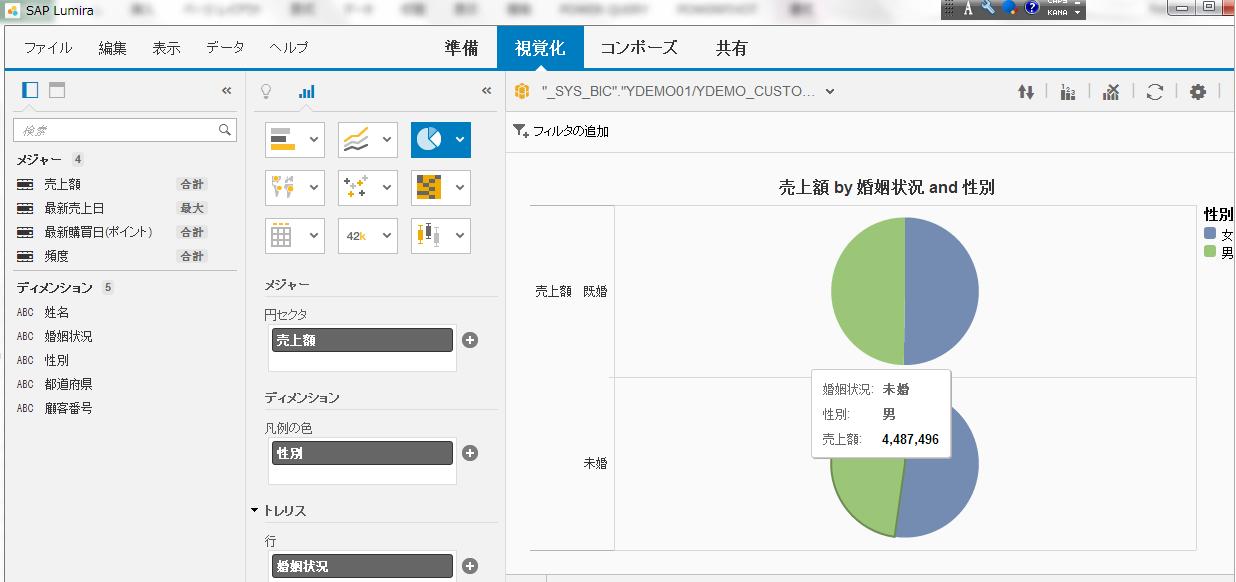
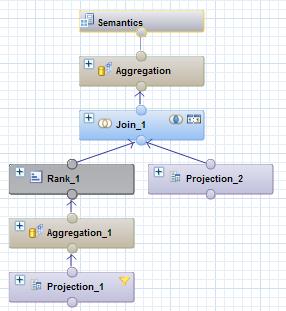
抽出元となるHANAで定義しているCalculation Viewは下図のようなモデルです。
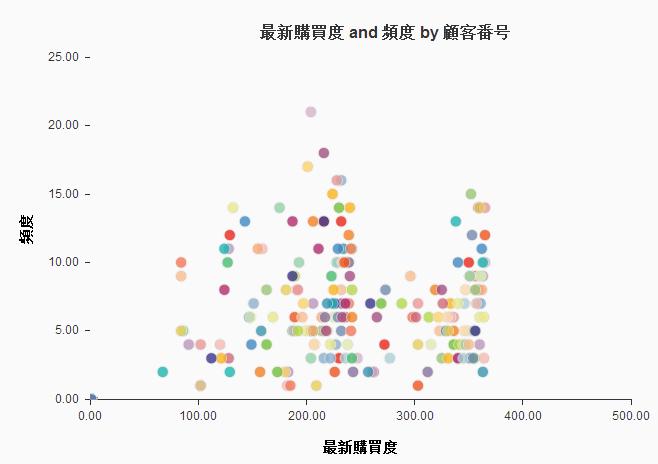
次に売上TOP300の上顧客の過去1年間の購買傾向を散布図形式で見てみます。横軸を「最新購買度」にして、右にいくほど最近買ってくれた顧客としています。縦軸を「頻度」として、上にいくほど多い回数買ってくれた顧客としています。大雑把に言うと左下が離反顧客、右上が上顧客です。
【手順2】Lumiraで抽出した顧客データをHANAに保存
次に手順1で抽出している顧客データをHANA側に保存します(技術的にはHANAでテーブル、Viewを定義し、Lumira Desktopのデータを登録しています)。下図がそのイメージです。Lumira DesktopからViewの定義対象パッケージ、テーブル等を入力していくだけです。同じSAP製品だけあって連携しやすいです。
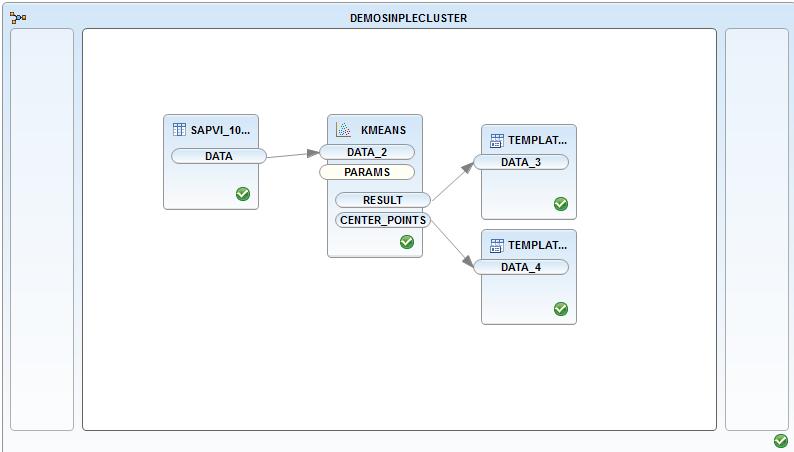
【手順3】顧客をいくつかのかたまり(クラスタ)に分類
今度は、HANAに格納した顧客をいくつかのかたまり(クラスタ)に分類します。今回はK平均法のクラスタリングを使って5クラスタに分類します。K平均法の具体的な内容については、Wikipedia等を参照ください。
HANA Studioから下図のAFMを使ってモデリングをします。手順2で登録した顧客データにPALのKmeans(K平均法)を使って5つのクラスタ番号を付番しています。
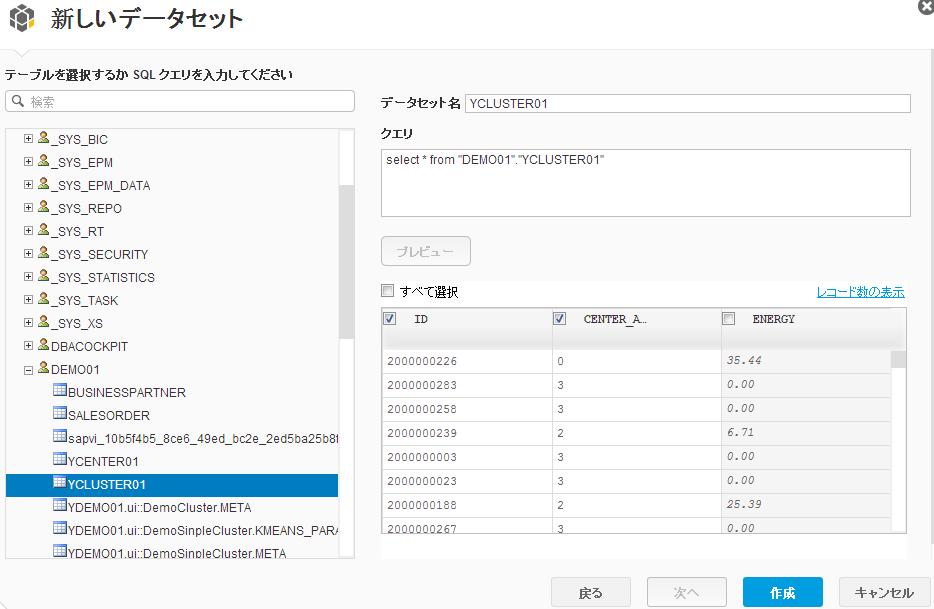
【手順4】顧客分類結果を確認
Lumira Desktopで手順3の結果である分類された顧客データをダウンロードします。
次にダウンロードしたデータと手順1のデータセットを結合して、両データが使えるようにします。顧客番号で結合をします。
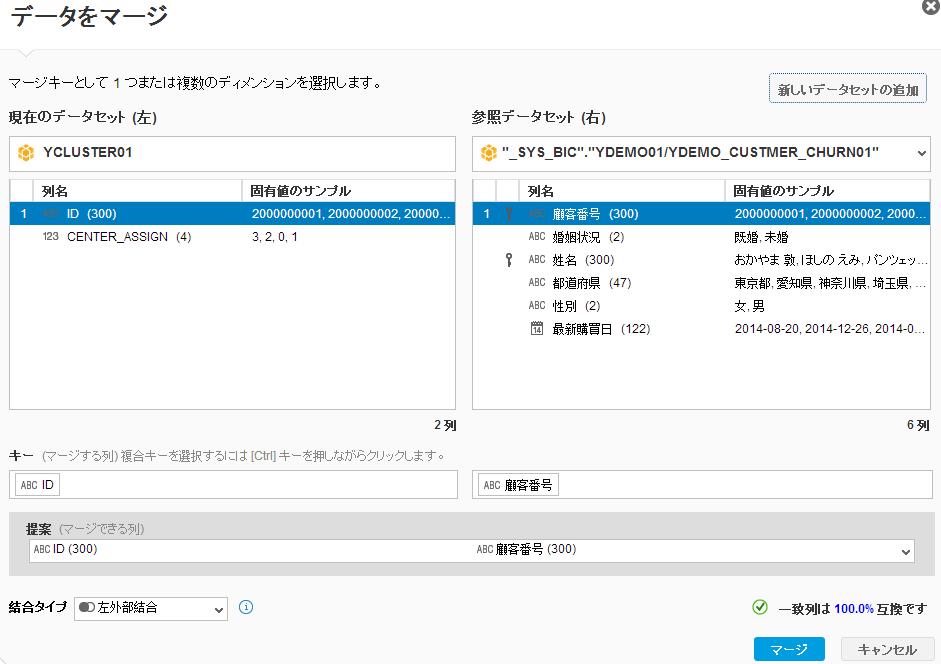
クラスタリングした結果を確認します。色ごとに顧客が5つに分類されていることがわかります(少しわかりにくいですが左下に1回も購入していない顧客が分布されています)。当然、クラスタ数によって結果が変わりますので、意図したものと違う結果の場合は何度がやり直します。
この結果を受けて左側の2つのクラスタの顧客に対してイベント案内を出すなどのアクションへとつなげて行けます。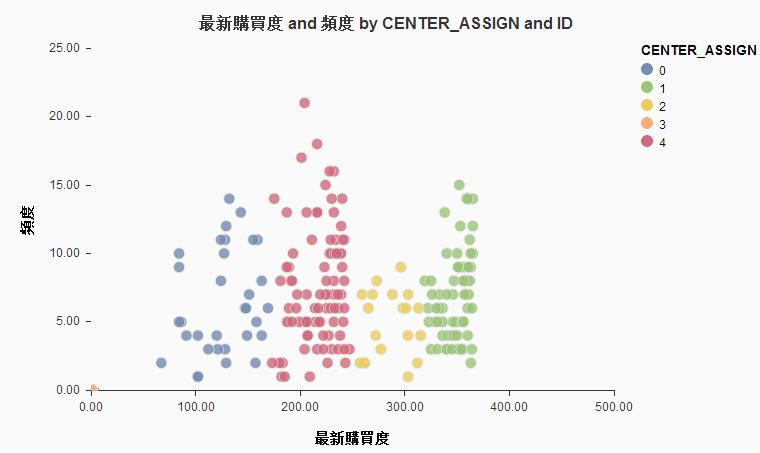
まとめ
今回はノーコーディングでの顧客分析をするデモシナリオを紹介しました。ユーザや状況ごとに分析要件は変わりますが、今回の方法を基礎として応用が効くはずです。例えばPALの回帰分析を使うなど対応範囲はいくつも考えられます。
次回は、「S4/HANAの勘所:HANA応用実践編(PALとUI5を使った顧客分析)」ということで今回の応用編です。開発を加えると何ができるか、というところまで踏み込みます。