iPhone盗難とクラウド
今回はAWSサービスを使った現実世界の情報収集から蓄積までを解説します。
なお本記事は、下記シリーズ記事の一部で、他記事も参照されることをお勧めします。
1/6 概要編:S/4HANA, Vora & Spark on AWSから生まれる価値
2/6 収集・蓄積:S/4HANA, Vora & Spark on AWSから生まれる価値【本記事】
3/6 抽出・統合:S/4HANA, Vora & Spark on AWSから生まれる価値


4/6 機械学習:S/4HANA, Vora & Spark on AWSから生まれる価値
5/6 見える化:S/4HANA, Vora & Spark on AWSから生まれる価値
6/6 SNS連携:S/4HANA, Vora & Spark on AWSから生まれる価値
昔と異なる検討方針
現実世界の情報の代表であるIoTに対応したシステムを検討する時に、検討方針が昔と異なります。代表的な事項を下図で示しました。
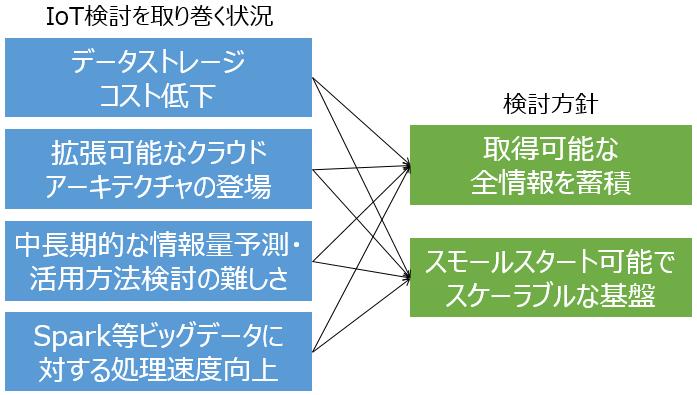
ひと昔前であれば、必要最低限の情報をシステムに蓄積し、将来的なピークの姿に耐えられるように基盤設計をすることが標準的でした。しかし、データストレージコストが低下し、クラウドのような拡張可能なアーキテクチャが登場しました。情報増加は費用に与える影響が少なくなり、その一方でSparkや機械学習などの処理技術の進化により新しい価値を生み出す手段が増えました。そのための基盤として従量課金のクラウドサービスを使うことで概念検証を小さく早く進め、稼働後に段階的なスケールアウトが容易にできます。このあたりの検討方法は、クラウドアーキテクティング原則が非常に参考になります。
収集から蓄積までの処理
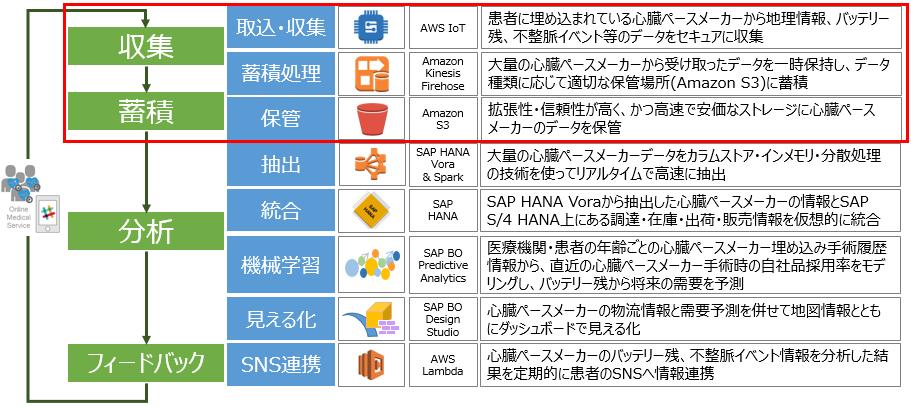
AWS IoT:さまざまなデバイスに対応したIoTデータ取込・収集
Amazon Kinesis Firehose:柔軟なストリーミング処理
AWS IoTから直接Amazon S3へ連携してもいいのですが、Amazon Kinesis Firehoseを使うことで複数デバイスから来る一定期間のデータをまとめてファイル化することができます。仮に10秒間隔で100デバイスからリクエストを受け取ると、Amazon Kinesis Firehoseがない場合ではAmazon S3に1000ファイルが生成されてしまいますが、Amazon Kinesis Firehoseを使うことで1ファイルに統合することができます。
Amazon S3:安価で安定したストレージサービス
Amazon S3はAmazon Simple Storage Serviceの略でストレージサービスです。ウェブスケールのコンピューティングを開発者が簡単に利用できるよう設計されています。SparkやHadoopに組み込まれている標準APIを使って連携することもできます。今回はHANA Voraから直接読み込んでいます。ソリューション概要はこちらのスライドがわかりやすいです。
AWSサービス設定手順
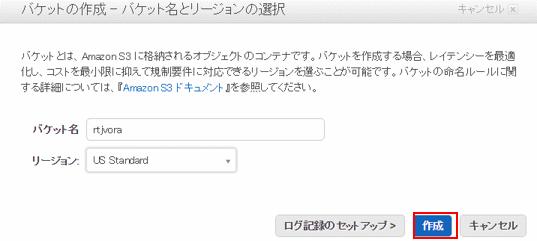
Amazon S3でバケット作成
手順は非常に簡単で、バケット名とリージョンを選択するだけです。
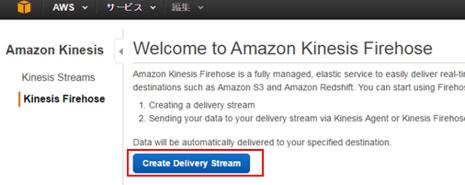
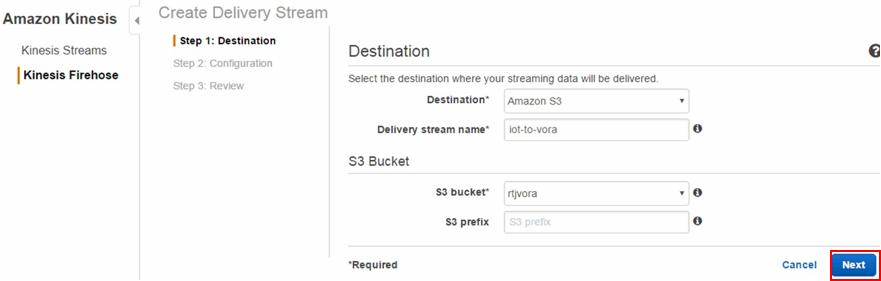
Amazon Kinesis FirehoseでDelivery Stream定義
まずは「Create Delivery Stream」ボタンを押します。
次に保存先として先のステップで作成したAmazon S3の情報を入力していきます。
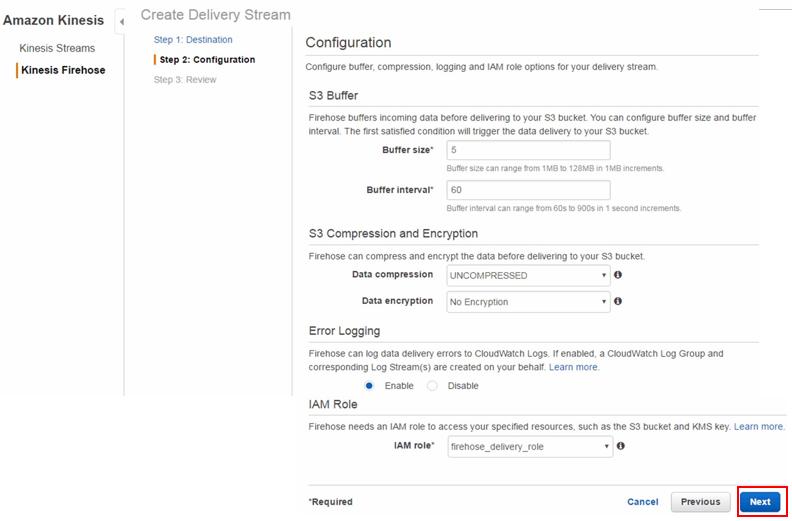
ConfigurationのステップではAmazon S3に保存する設定をします。シンプルに圧縮や暗号化はせず、60秒ごとに書き込む設定にしました。スクリーンショットは載せませんが、Amazon S3に書き込む権限を持つIAM Roleを登録しています。最後に定義内容を確認して登録です。
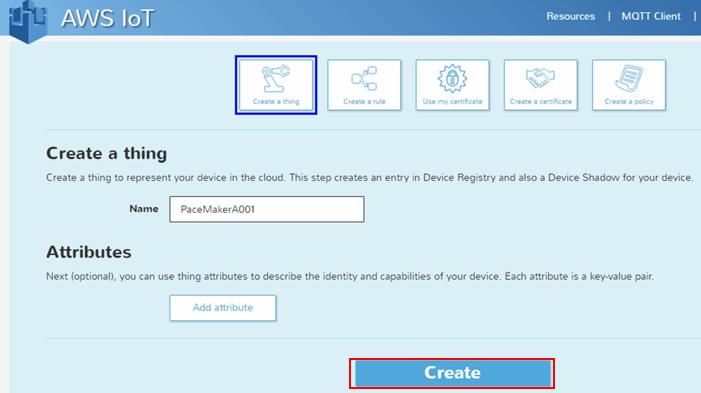
AWS IoTでThingとRuleの定義
まずは、個別デバイスを認識するThingを登録します。
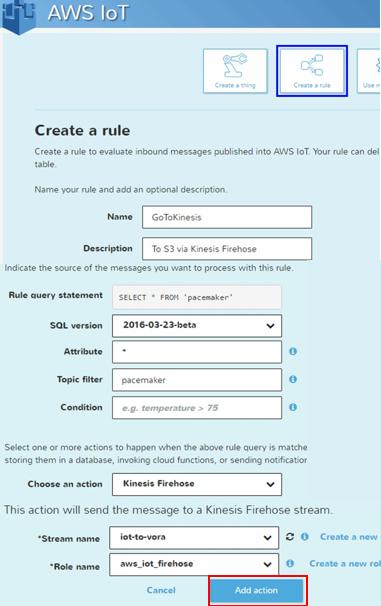
最後にAWS IoTからAmazon S3まで繋がるかを疎通確認します。テストツールのMQTT Clientを使います。
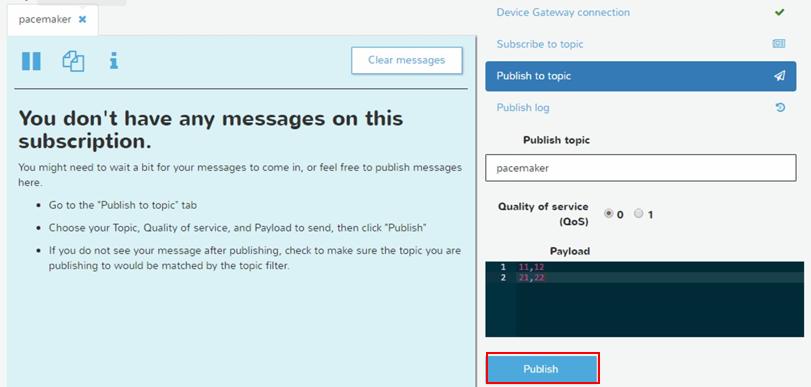
Amazon S3のバケットにファイルが書き込まれていることを確認できました。今回は実際に心臓ペースメーカーのようなThingの実物からの接続は割愛します。
マイクロサービスの魅力
もっと読む:SAP S/4HANAで何が実現できるのか?

この記事に関するサービスのご紹介

導入/移行(プロフェッショナル)サービス
プロフェッショナルサービスでは主にSAPシステムの導入や移行、それに伴うテクニカルな支援を行います。ERPやS/4 HANA、SolManといった様々なSAP製品の新規導入、クラウドを含む様々なプラットフォームへのSAPシステムの最適な移行、保守切れに伴うバージョンアップ・パッチ適用等の作業だけでなく、パラメータ設計、パフォーマンスチューニング、導入・移行計画支援等についても対応いたします。
詳細はこちら