VHSデッキ生産撤退と記録媒体の変化
なお本記事は、下記シリーズ記事の一部で、他記事も参照されることをお勧めします。
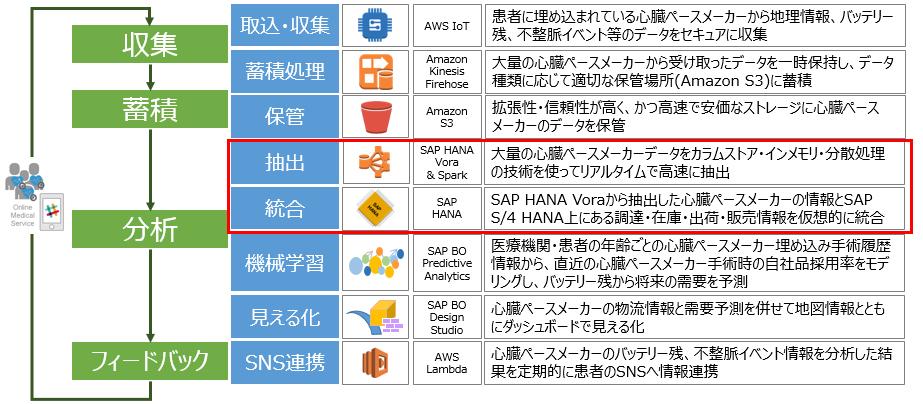
1/6 概要編:S/4HANA, Vora & Spark on AWSから生まれる価値
2/6 収集・蓄積:S/4HANA, Vora & Spark on AWSから生まれる価値
3/6 抽出・統合:S/4HANA, Vora & Spark on AWSから生まれる価値【本記事】


4/6 機械学習:S/4HANA, Vora & Spark on AWSから生まれる価値
5/6 見える化:S/4HANA, Vora & Spark on AWSから生まれる価値
6/6 SNS連携:S/4HANA, Vora & Spark on AWSから生まれる価値
また、HANA Voraに関しては、以前の記事「HANA Voraの基本機能を読み解く~インメモリクエリエンジン他~」も参照ください。SCNの「SAP HANA Vora 日本語情報まとめ」まとめ記事もわかりやすいです。
HANA Voraアーキテクチャ
SAPシステムに長く携わっていて、HadoopやSparkについて馴染みのない方も多いはずです。まずは、Hadoop・Spark・HANA Voraを比較すると下図にまとめました(わかりやすさに重点を置いたため、正確性は欠いています)。
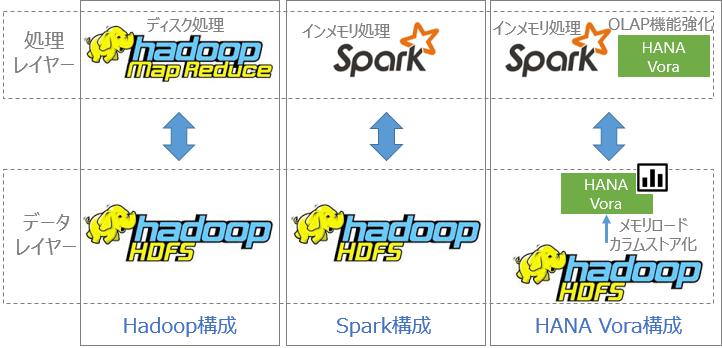
HANA VoraはHadoopのデータレイヤーとSparkの処理レイヤーにHANAで培ったインメモリ・カラムストアの技術を組み込んで処理高速化を実現しています。
冒頭で「HANAとは対局の考え方にある」と書いたのは、Hadoop・Spark・HANA Voraが複数廉価サーバーで分散処理することを前提に設計されている点です。小さいデータに対して簡単な処理をする場合には、一般的なRDBMSや言語と比べて非常に遅いです。一方で、HANAはハードウェア認定が必要で単一サーバで最適に動く処理が多いです(スケールアウト構成の方が最適な場合もあります)。
この辺は後日、詳しい内容を別記事で解説します。
抽出・統合処理
IoTとしてAmazon S3に蓄積された心臓ペースメーカーの情報(バッテリー情報など)をHANA VoraとSparkで抽出してHANA上でS/4 HANAの調達・在庫・出荷・販売情報と統合します。
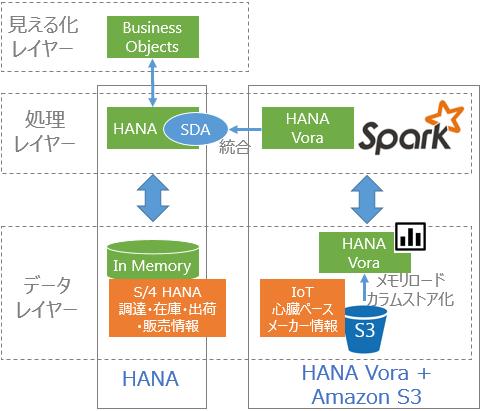
抽出・統合の設定開発
HANA Voraテーブル定義
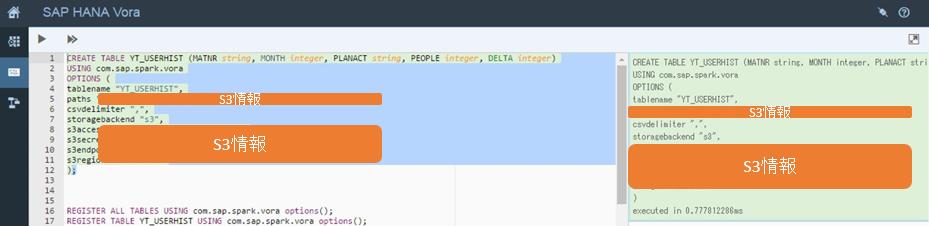
テーブル定義によって、ディスクからメモリにカラムストア化されてデータロードされた状態になり、高速で抽出処理ができる状態になりました。HANA Voraの制御によって自動的にデータが各ノードに分散されます(しない方法もあります)。
HANAで仮想テーブル定義

HANA View定義
仮想テーブルを定義した後は、S/4 HANAのテーブルと併せてHANA View(Information View)を定義するだけです。仮想テーブルは通常のテーブルとほぼ同様に扱え、特別変わったことがありませんので画面ショットは省略します。
※HANAのSPSに応じてHANA Viewの種類や定義方法には注意してください。
HANA Voraを実測してみました
| 処理内容 | 処理時間 | 抽出元テーブル件数 | 抽出件数 | (集計後)出力件数 |
|---|---|---|---|---|
| 10億件から2件の5項目を取得 | 0.4秒 | 1,025,622,517件 | 2件 | 2件 |
| 10億件から6000万件をsum関数で計算(1項目のみ) | 5秒 | 1,025,622,517件 | 62,411,529件 | 1件 |
Hadoop、Spark、HANA Voraとクラウドの相性の良さ
企業における記録媒体
一方、管理者からすると、情報内容に応じて処理速度や管理コストの点から記録媒体に置くことが求められます。そのような管理者側の目線に立った時の一つの有力な選択肢がHadoopやAmazon S3であり、データ複製をしないで高速処理化できるのがHANA Voraです。VHSからDVD、ブルーレイディスクに進化したように、企業における記録媒体もRDBMS以外の大容量・高速処理の選択肢が普及されつつあります。
この記事に関するサービスのご紹介

導入/移行(プロフェッショナル)サービス
プロフェッショナルサービスでは主にSAPシステムの導入や移行、それに伴うテクニカルな支援を行います。ERPやS/4 HANA、SolManといった様々なSAP製品の新規導入、クラウドを含む様々なプラットフォームへのSAPシステムの最適な移行、保守切れに伴うバージョンアップ・パッチ適用等の作業だけでなく、パラメータ設計、パフォーマンスチューニング、導入・移行計画支援等についても対応いたします。
詳細はこちら